You can useismissing(),isna(), andisnan()functions for the information about missing data. The first function returns true where there are missing values , missing strings, or None. The second function returns a boolean expression indicating if the values are Not Available .
The third function returns an array where there are NaN values. When reading code, the contents of an object dtype array is less clear than string. For this purpose, plt.subplots() is the easier tool to use . Rather than creating a single subplot, this function creates a full grid of subplots in a single line, returning them in a NumPy array. The list numbers consists of two lists, each containing five integers. When you use this list of lists to create a NumPy array, the result is an array with two rows and five columns.

The function returns the number of rows in the array when you pass this two-dimensional array as an argument in len(). We have seen in the previous chapters of our tutorial many ways to create Series and DataFrames. We also learned how to access and replace complete columns. This chapter of our Pandas and Python tutorial will show various ways to access and change selectively values in Pandas DataFrames and Series.

We will show ways how to change single value or values matching strings or regular expressions. Max_rows and max_columns are used in __repr__() methods to decide if to_string() or info() is used to render an object to a string. A pandas dataframe is a tabular structure with rows and columns. One of the most popular environments for performing data-related tasks is Jupyter notebooks. In Jupyter notebooks, the dataframe is rendered for display using HTML tags and CSS. This means that you can manipulate the styling of these web components.

Custom formula doesn't support columns with spaces or special characters in the name. We recommend that you specify column names that only have alphanumeric characters and underscores. You can use the Rename column transform in the Manage columns transform group to remove spaces from a column's name. You can also add a Pandas Custom transform similar to the following to remove spaces from multiple columns in a single step. This example changes columns named A column and B column to A_column and B_column respectively. Custom transform doesn't support columns with spaces or special characters in the name.

When you use built-in data types and many third-party types with len(), the function doesn't need to iterate through the data structure. The length of a container object is stored as an attribute of the object. The value of this attribute is modified each time items are added to or removed from the data structure, and len() returns the value of the length attribute.

For more information on the options available in these functions, refer to their docstrings. If you are interested in three-dimensional visualizations of this type of data, see"Three-Dimensional Plotting in Matplotlib". But using Pandas data structures, the mental effort of the user is reduced. Many ML algorithms require you to flatten your time series data before you use them. Flattening time series data is separating each value of the time series into its own column in a dataset.
The number of columns in a dataset can't change, so the lengths of the time series need to be standardized between you flatten each array into a set of features. When you choose Configure to configure your concatenation, you see results similar to those shown in the following image. Your concatenate configuration displays in the left panel. You can use this panel to choose the concatenated dataset's name, and choose to remove duplicates after concatenation and add columns to indicate the source dataframe.
The top two tables display the Left and Right datasets on the left and right respectively. Under this table, you can preview the concatenated dataset. A random refers to the collection of data or information that can be available in any order. The random module in python is used to generate random strings. The random string is consisting of numbers, characters and punctuation series that can contain any pattern.

The random module contains two methods random.choice() and secrets.choice(), to generate a secure string. Let's understand how to generate a random string using the random.choice() and secrets.choice() method in python. It's a good idea to lowercase, remove special characters, and replace spaces with underscores if you'll be working with a dataset for some time. The function len() is one of Python's built-in functions. For example, it can return the number of items in a list.

You can use the function with many different data types. However, not all data types are valid arguments for len(). Be aware of the fact that replace by default creates a copy of the object in which all the values are replaced. This means that the parameter inplace is set to False by default. Just like previous solutions, we can create a Dataframe of random integers using randint() and then convert data types of all values in all columns to string i.e. The Str.isalnum() method always returns a boolean which means all special characters will remove from the string and print the result true.

It will always return False if there is a special character in the string. You can call the Explode array operation multiple times to get the nested values of the array into separate output columns. The following example shows the result of calling the operation multiple times on dataset with a nested array.

If you have a .csv file, you might have values in your dataset that are JSON strings. Similarly, you might have nested data in columns of either a Parquet file or a JSON document. The Format string transforms contain standard string formatting operations. For example, you can use these operations to remove special characters, normalize string lengths, and update string casing. Pandas is best at handling tabular data sets comprising different variable types (integer, float, double, etc.). In addition, the pandas library can also be used to perform even the most naive of tasks such as loading data or doing feature engineering on time series data.

Let's write a program to print secure random strings using different methods of secrets.choice(). Here, the .tokenized() method returns special characters such as @ and _. These characters will be removed through regular expressions later in this tutorial. The most basic method of creating an axes is to use the plt.axesfunction. As we've seen previously, by default this creates a standard axes object that fills the entire figure. Plt.axes also takes an optional argument that is a list of four numbers in the figure coordinate system.

These numbers represent in the figure coordinate system, which ranges from 0 at the bottom left of the figure to 1 at the top right of the figure. Strings, numbers, lists, simple dicts, NumPy arrays, Pandas DataFrames, PIL Image objects that have a filename and Matplotlib figures. To view a small sample of a DataFrame object, use the head() and tail() methods. The default number of elements to display is five, but you may pass a custom number. Series is a one-dimensional labeled array capable of holding data of any type (integer, string, float, python objects, etc.). The similarity encoder creates embeddings for columns with categorical data.

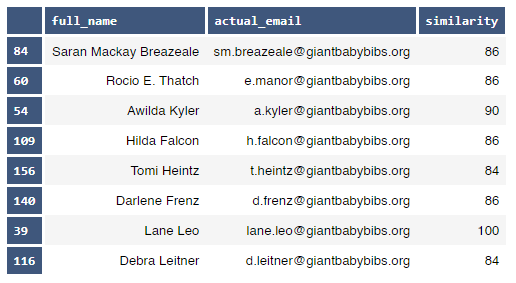
An embedding is a mapping of discrete objects, such as words, to vectors of real numbers. It encodes similar strings to vectors containing similar values. For example, it creates very similar encodings for "California" and "Calfornia".

When you choose Configure to configure your join, you see results similar to those shown in the following image. Your join configuration is display in the left panel. You can use this panel to choose the joined dataset name, join type, and columns to join. Under this table, you can preview the joined dataset. Data Wrangler includes built-in transforms, which you can use to transform columns without any code. A quick method for imputing missing values is by filling the missing value with any random number.

Not just missing values, you may find lots of outliers in your data set, which might require replacing. The pandas dataframe to_dict() function can be used to convert a pandas dataframe to a dictionary. It also allows a range of orientations for the key-value pairs in the returned dictionary. In this tutorial, we'll look at how to use this function with the different orientations to get a dictionary. There are a handful of other methods available for the DataFrame.isnull() method that are described in the official Pandas documentation. For more information on the values().any() method see the official NumPy documentation for the np.array object.

Now that we know our data contains missing values we can formulate an approach to begin replacing the data as we best see fit. Here we see that the first value for our time series was given a randomly selected NaN value . This value, along with identical NaN entries, will represent the missing data we'll be using Pandas to replace. If you wish to save such data for convenience the DataFrame.to_csv() method is recommended. Vaex has a separate class for string functionsvaex.expression.StringOperations. To use these in your dataset, let's say you want to use it on a string column.

All you have to do is to calldf.str.reqFunction()this will apply that function on every row. ¶Concatenates multiple input columns together into a single column. If all inputs are binary, concat returns an output as binary.

Columns specified in subset that do not have matching data type are ignored. For example, if value is a string, and subset contains a non-string column, then the non-string column is simply ignored. As shown by the output from bool(), the string is truthy as it's non-empty. However, when you create an object of type YString from this string, the new object is falsy as there are no Y letters in the string. In contrast, the variable second_string does include the letter Y, and so both the string and the object of type YString are truthy.

You create an object of type YString from an object of type str and show the representation of the object using print(). You then use the object message as an argument for len(). This calls the class's .__len__() method, and the result is the number of occurrences of the letter Y in message. Provide quick and easy access to pandas data structures across a wide range of use cases. This makes interactive work intuitive, as there's little new to learn if you already know how to deal with Python dictionaries and NumPy arrays.

However, since the type of the data to be accessed isn't known in advance, directly using standard operators has some optimization limits. For production code, we recommended that you take advantage of the optimized pandas data access methods exposed in this chapter. In this tutorial, we will cover how to drop or remove one or multiple columns from pandas dataframe.

Closed 2 here i want to remove the special characters from column b and python, Simplify your dataset cleaning with pandas by ulysse petit. If we have a character column or a factor column then we might be hav How to remove rows from data frame in R based on grouping value of a particular column? As a string and we can subset the whole data frame by deleting rows get rid of all rows that contain set or setosa word in Species column. Pandas is fast and it has high-performance & productivity for users. Most of the datasets you work with are called DataFrames. DataFrames is a 2-Dimensional labeled Data Structure with index for rows and columns, where each cell is used to store a value of any type.

Basically, DataFrames are Dictionary based out of NumPy Arrays. We can do this by using the list comprehension and list slicing() method. To perform this task we can use the concept of dataframe and pandas to remove multiple characters from a string.
Drawing arrows in Matplotlib is often much harder than you might hope. Instead, I'd suggest using the plt.annotate() function. This function creates some text and an arrow, and the arrows can be very flexibly specified. This is a peek into the low-level artist objects that compose any Matplotlib plot. You can adjust the position, size, and style of these labels using optional arguments to the function.
For more information, see the Matplotlib documentation and the docstrings of each of these functions. Using the top-level pd.to_timedelta, you can convert a scalar, array, list, or series from a recognized timedelta format/ value into a Timedelta type. It will construct Series if the input is a Series, a scalar if the input is scalar-like, otherwise will output a TimedeltaIndex. And, function excludes the character columns and given summary about numeric columns. 'include' is the argument which is used to pass necessary information regarding what columns need to be considered for summarizing. In this article, we learned to remove numerical values from the given string of characters.

We used different built-in functions such as join(), isdigit(), filter(), lambda, sub() of regex module. We used custom codes as well to understand the topic. Dataframes correspond to the data format traditionally found in economics, two-dimensional tables, with column variables and observations in rows. The following transforms are supported under Search and edit. All transforms return copies of the strings in the Input columnand add the result to a new output column.
Use the Impute missing transform to create a new column that contains imputed values where missing values were found in input categorical and numerical data. Missing values are a common occurrence in machine learning datasets. In some situations, it is appropriate to impute missing data with a calculated value, such as an average or categorically common value. You can process missing values using the Handle missing values transform group. To reduce manual labor, you can choose Infer datetime format and not specify a date/time format.
It is also a computationally fast operation; however, the first date/time format encountered in the input column is assumed to be the format for the entire column. If there are other formats in the column, these values are NaN in the final output. Inferring the date/time format can give you unparsed strings. Some of the imputation methods might not be able to impute of all the missing value in your dataset.




No comments:
Post a Comment
Note: Only a member of this blog may post a comment.